CMU-15-445——P1
实现Buffer Pool Manager。其中使用了Extendible Hashing数据结构以及改进版LRU-K置换算法。
Extendible Hashing
先简单介绍两个常见的hash实现
Linear Probe Hashing
用环形array slots来存储
增:hash出位置,然后添加,如果已存在,则找下一个最近的slot
查or改:与增相似,先hash出位置,然后比较存储的key与查询的key是否相等。如果不相等则后延。直到查询的位置为空,或者全部查询过一遍。
删:为了不让未来某些key在此处停止后延,一般的方式是将位置标记为tombstones,代表记录被删除了,但是依旧要后延去找。
Chained Hashing
将每个slot改为一个linked list,所有碰撞的都在list中。用一个bucket来管理多个碰撞的entry,比如bucket是一页4K。
缺点:如果空间最开始开小了,可能会导致后续list太长,从而导致查询慢。
以上的两种实现方式在空间用完的时候,需要开辟一块新空间重新构建新hash表,并复制所有原有元素。
Extendible Hashing
目的:让大部分entry别动。改变少部分entry。
做法:通过slots的部分bits来划分bucket,当bucket满了的时候,分裂为两个。将该bucket中的entry重新hash。
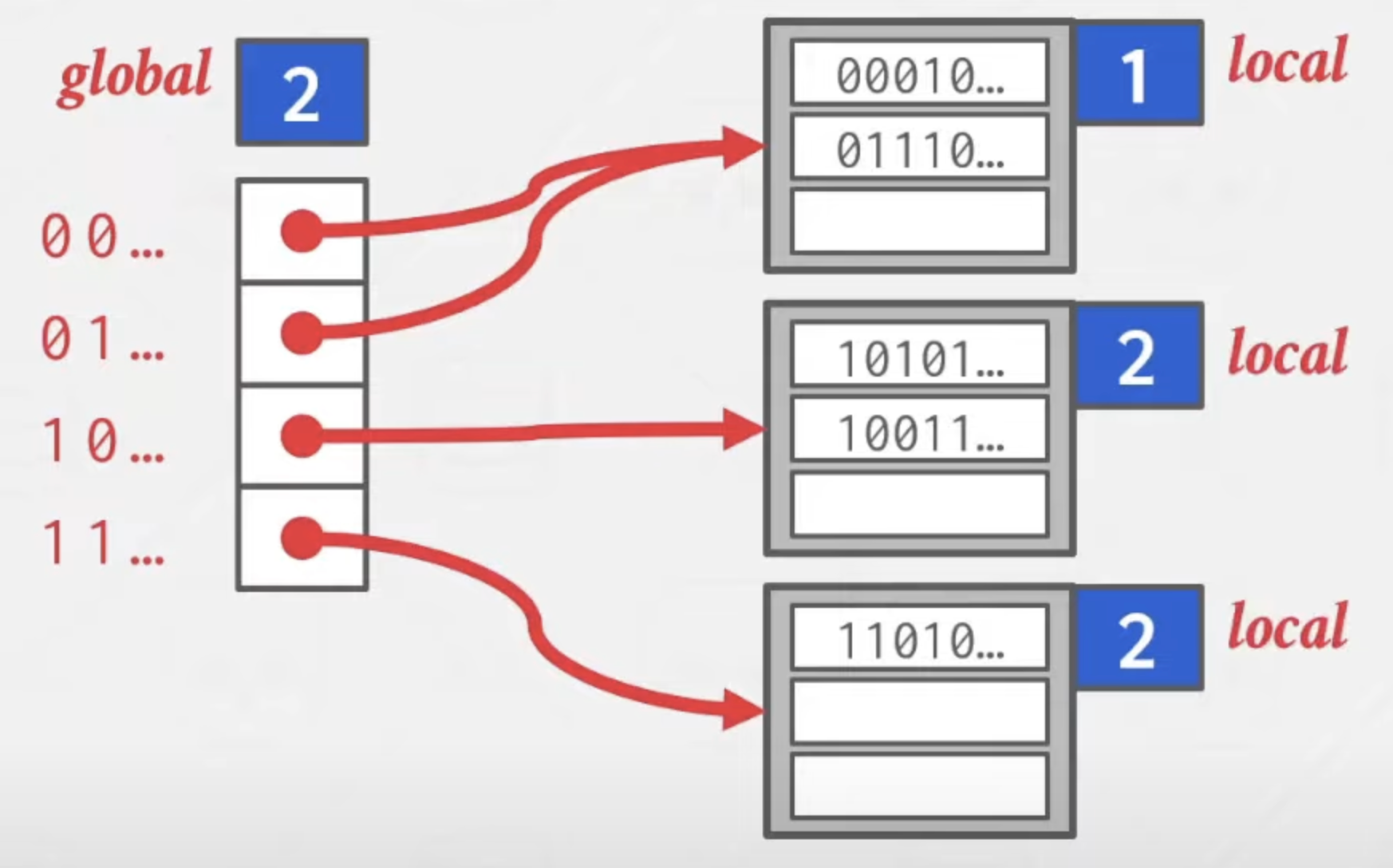
如果部分slots的bucket使用率低,那么可以共用slots,允许存在不同slots指向相同的bucket。
在使用的时候,看global depth,代表我们查询时需要的bits数量。
比如Put B,hash:10111:
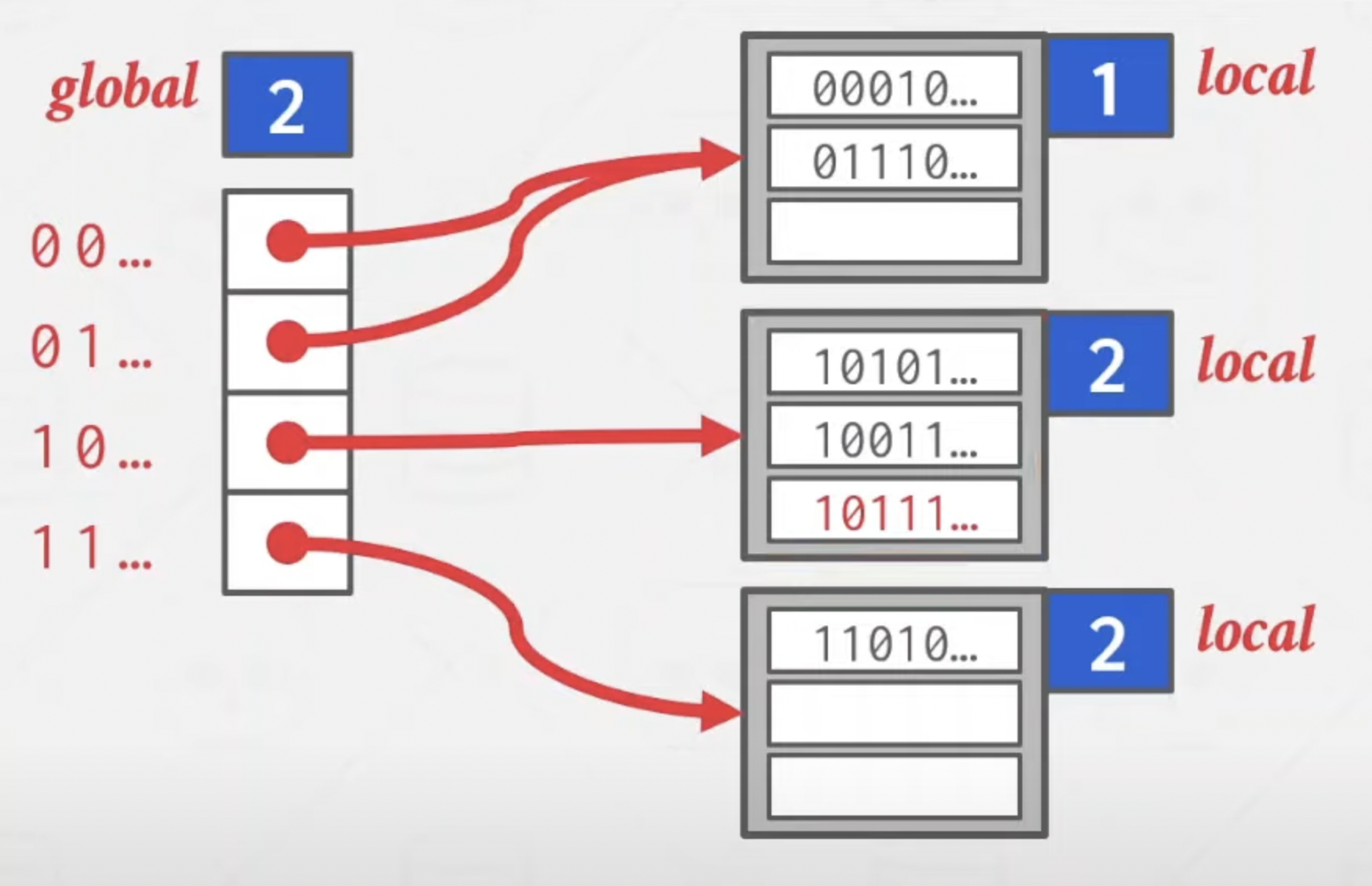
再添加Put C,hash:10100,发现bucket满了。于是,将bucket切分为两个,然后重新hash自身包含的entries,并修改指向自己的那些指针(本来指向同一个,现在需要根据key来指向切分出来的两个),自身depth加1
由于bucket的depth大于global,于是将pointer的list翻倍:

而其他的bucket不受影响。
再来一个🌰
例如,假设global depth为5,0x11100号bucket此时已经满了,假设local depth为3(也即考虑最后3位),我们需要往其中再新增entry,此时如何扩容?
- 在考虑3位的情况下,该bucket为0x100。
- 首先,生成两个depth为4的bucket:0x0100,0x1100。
- 筛选出有哪些指针收到影响:后面3位与0x100相同
- 修改这些指针:根据右往左第4位决定这个指针指向0x0100还是0x1100。
- 将原本0x100 bucket中的entry重新分配,它们一定会hash到新bucket(0x0100或者0x1100)中。
LRU-K
paper:https://www.cs.cmu.edu/~natassa/courses/15-721/papers/p297-o_neil.pdf
LRU
记录每次访问的timestamp,淘汰最早的。可以用队列位置代表timestamp,用hash表快速找到位置
LRU的问题
假设LRU Size=3,假设第一个请求Q1访问了Page0,Page0加入LRU。
然后Q2需要扫描Pages。于是访问了Page0,1,2。依次加入LRU。
再访问Page3的时候,将谁淘汰?(LRU会淘汰0)(LRU-K则会淘汰1)
假设Q3与Q1相同。再次访问Page0。那么LRU-K算法可以命中,而LRU算法miss。
LRU-K的做法
每个Entry记录其K个历史访问timestamp。当前时间减去K次中最早的那次访问时间作为k-distance。淘汰k-distance最大的entry。不足k次记录,k-distance为+inf。如果有多个+inf,则按LRU,淘汰最早的。
Buffer Pool Manager
作用是选择部分磁盘上的page进行cache到内存中。它需要做到透明性,用它的时候完全不需要知道frame或者page table映射相关的东西,直接操作page就行。
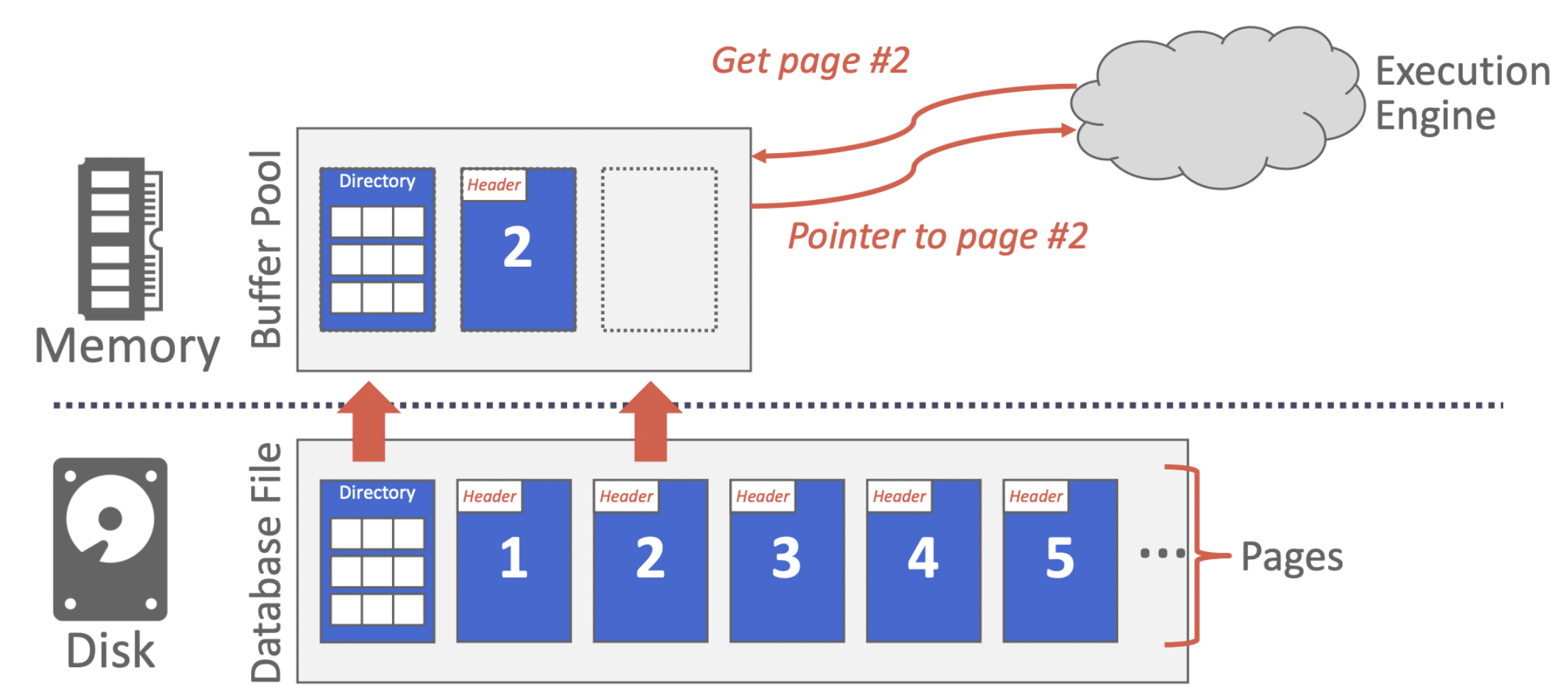
Buffer Pool:内存中的一个array,里面每个frame可以放入page
Page Directory:一个映射,从磁盘找page,必须持久化
Page Table:一个映射,从Buffer Pool上找page,从page id到frame id

当然Page Table也不仅仅是一个映射,还存了一些其他信息:
- dirty-flag,代表是否有线程写过该page
- reference计数器,代表此时是否有正在使用该page的线程。如果有就不能evict该page。